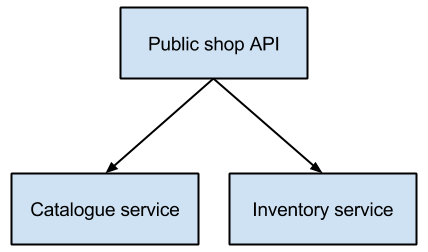
For example: in Qandidate.com we have companies that register for an account, but not everybody that registered actually starts using the system. We have a report about active companies, where the definition of active is determined by combining multiple events. But at some point we might change the definition of active. With replaying we have the possibility to revisit those events and create new reports based on the new defintion of active.
It also allows for error correction. Whenever you find a bug in one of your read models, you can simply fix the bug and recreate your read models by replaying the events.
In this post we will go through the process of replaying events.
]]>At Qandidate.com we had to implement file uploads as well. Besides the regular upload it should also support selecting files from cloud services like Google Drive and Dropbox. Instead of trying to implement all integrations ourselfs we decided to look for services that could handle this for us. We found filepicker, a service that supports 22 sources out of the box. Besides selecting files from your computer you can also select files from Dropbox, Google Drive, Facebook, SkyDrive or even from FTP.
]]>So when you need to query some data, you can replay your eventstream and listen to specific events you are interested in. Although this can work for quite a lot of cases, most of the time this is not very efficient and it doesn't scale very well.
One solution to solve that, is to use projections to create a view that you can query against. Those projections are created with a projector. A projector listens to events and creates a read model from it. With this method it is really easy to create multiple read models at the same time. Because of the nature of your event stream, collecting facts that happened in the past, you can also easily create new read models for events that happened a long time ago.
]]>So Fritsjan started with the demo application a while back and we just published it on Github. In this blog post we want to take a closer look at the demo application.
]]>On Tuesday 4 November we announced our Series A investment by Randstad Innovation Fund and Qmulus. A really exciting moment for the whole team. This is the starting point we all were waiting for and it feels like having trained all these years for the Champions League and now finally stepping on the grass to perform. We are growing, in fact we were already growing fast, but with this investment we can ramp up our activities and execute our growth plans at an even faster pace. Please also check out this article on Techcrunch about why Randstad Innovation Fund invests in companies like Qandidate.com.
]]>One of the pull requests we received is from simensen. He added factories for our aggregates.
]]>In order to achieve this we decided to add a request id to each of our requests. We can now add the request id to the command log and add the request id to the metadata of our DomainMessages using the MetadataEnricherInterface
There are some webservers that provide a solution for this problem. One of these is an nginx module, and there is also an apache module. However, we wanted our solution to be webserver-independent. The result: we decided to tackle our problem the way we know best; in PHP.
We created a middleware for Symfony that adds a request id header to the request's headers. Check out the source code. You can add it to your application by changing a few lines of code in your app.php file. Just have a look at these 'before' and 'after' codeblocks:
]]>But another thing, and probably even more important, you should always try to make sure your changes are backwards compatible. That would mean there is a lot of thinking involved before the actual API is built, but it can also save you from a big, very big headache.
]]>]]>
So far we encountered a number of advantages of working with microservices, and we would like to share our findings with you. Note that we don't run many microservices in our production environment yet. Who knows how we will be developing software in six months!
]]>In this blog post I will explain how to store geocodes in MariaDB and ElasticSearch and how to calculate the distances between them.
]]>When we deployed our first AngularJS application over at Qandidate.com a single page view would generate a whopping 56 HTTP requests of which 32 were our own AngularJS files like controllers and services and 12 were 3rd party dependencies.
Since browsers only allow for up to about 8 parallel connections a lot of requests will have to wait for other requests to finish resulting in a poor end-user experience.
In this blog post I will show how you can safely minify and concatenate your AngularJS code.
]]>The demo itself shows a working circuit breaker, but I didn’t explain how Phystrix actually works. This blog will go through the demo code and show the changes we had to make to get Phystrix running asynchronously, while also looking more in-depth as to how Phystrix actually works. Awesome!
]]>Did I say server communication? We use Symfony 2 (which is awesome too) for our back end API’s. Unfortunately AngularJS and Symfony do not speak the same language out-of-the-box.
In this post I will show you how we automatically decode JSON requests so we can use it with Symfony's Request object using our symfony-json-request-transformer library (or class actually).
]]>
In this post I will show you how to organize your server configuration using playbooks and roles. As an example we will install MariaDB 10.0 beta.
]]>I had to use trial and error to get the new server up and running and still I wasn't confident everything was properly installed. What I needed at that time was a way to manage my server configuration.
In this blog post I will tell you about my experience with server provisioning, why I chose Ansible and I will show you how to install a web server.
]]>For most people the easiest way of debugging a PHP application is to place
var_dump() and die() statements all over the code. Another option is
installing xdebug, which has gotten a lot easier nowadays due to IDE
integrations.
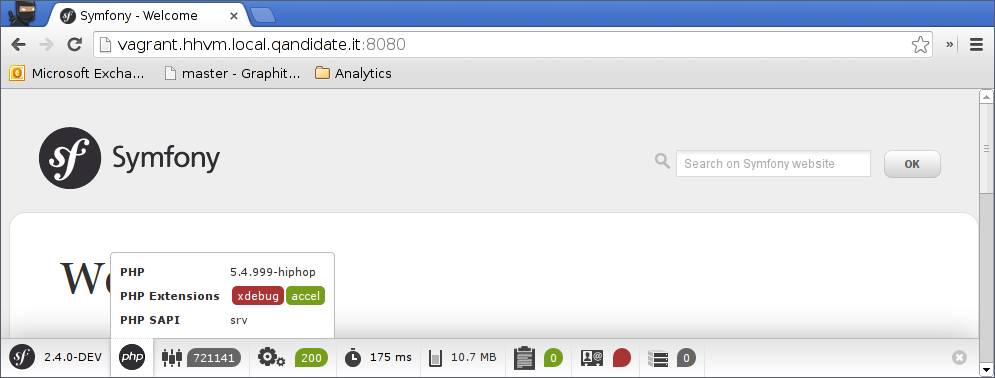
In this blog post we'll show you how to debug your PHP application using HHVM. We describe how you can step through your program, set and manage your breakpoints, how to inspect variables and take a peek at helpful features like conditional breakpoints.
]]>
What Facebook says about HipHop:
HipHop is Facebook's complete toolchain for the PHP language: interpreter, JIT compiler and debugger.
Facebook.com was motivated to create HipHop to save recources on their servers. They claim to be 40% faster than their previous version that was in fact a PHP to C++ compiler which was already faster than plain PHP 1.
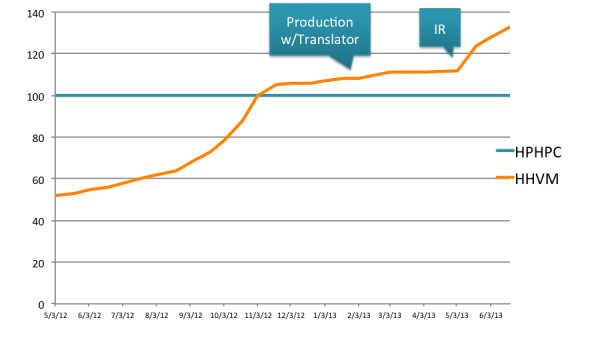
source: Wow HHVM is fast…too bad it doesn’t run my code
In this blog series we’ll get you started with hhvm. We’ll get the symfony standard edition running and show the ins and outs of debugging your code with hhvm (which is awesome!). Today, we’ll start of by setting up hhvm in your own vagrant box.
]]>In order to capture the things we learn during 20% time we've been blogging on an internal blog for some time now. A short while ago we decided we wanted to share what we've learned with the world and so this blog was born!
In the future we'll blog about all things PHP, our development process and all things development which aren't really PHP. Stay tuned!
In the meantime, enjoy one of our favorite cat gifs!
]]>